ժҪ�� �˹����ܺͻ���ѧϰ�������о��ںܴ�̶���ǿ����ͨ��ѧϰ��Խ��Խ���ѵ�����Լ�Խ��Խ��ļ��㡣 �෴���������һ������֪ģ��Ϊ���ĵĻ�ϣ�֪ʶ���������������ķ������÷�������Ϊ�ȵ�ǰ���ܵĸ��ḻ������׳��AI�ṩ������ 1.����ǿ����˹����� ����û������ȫ֪�����ѧϰ���˹����ܽ���δ����ʮ�귢չ�������������Ҫ�ﵽһ���µ�ˮƽ����ô��Ҫ���ǹ�ȥʮ����ѧ����֪ʶ����Ҫ�о���һ��Ӧ���о��Ķ����� �����ǽ����Ϊ��׳���˹�������ˮƽ����Ȼ��һ���dz��˻��������Ƶ����ܣ���������������ϵͳ�Ϳɿ��ķ�ʽ������ѧ֪ʶӦ�õ��㷺�������У��Ӹ���֪ʶ���ۺ�֪ʶ��Դ���������Ϳ�������̬�ض����������������һ�����Ƕ���ͨ�������������ķ�ʽ��������һ��������ѧ���Ķ���ת�Ƶ���һ�����С� ��ij��������˵������һ���������Ŀ�꣬�Ȳ����ˡ����˹����ܡ��������IJ�����Ҳû�����������ޱ��ʣ���Ҳ����������Ҫ��һ���������ǿ���ʵ�ֵģ��������Ҫʵ����һĿ�꣬����������Ҫ��һ�����������ǿ����������˹����ܣ������������ǵļ��У��ڵ�·�ϣ���ҽ���İ칫�Һ�ҽԺ������ҵ�л����������У����Ƕ����������� �����֮��������Dz���ָ���˹������ܹ��ɿ��ر��֣���ô���ǾͲ�Ӧ��������������Ȼ����ʵ������ˣ��ɿ��Բ��ܱ�֤���Ŷȣ��෴���ɿ��Բ��ܱ�֤���Ŷȡ���ֻ������ǰ������֮һ��������ֵ�����õĹ���ʵ���������Marcus��Davis��Marcus��Davis��2019�����н�һ�����ۡ��� �� ���˿��ܻὫǿ���AI��������������ܣ����Ժܺõ���ɵ�����խĿ�꣨���������ʶ��Ʒ�֣���ϵͳ���жԱȣ�����Щϵͳ�����Էdz���һ������Ϊ���ģ����Ҳ���׳����ת�Ƶ������ʶȲ�ͬ�Ļ��������磬����ͬ�ߴ�ĵ�·�壬���һ��������ͬ�����ַ������ò�ͬ����Ƶ��Ϸ����һ����Ƶ��Ϸ������������д�����������ѵ��������ЩϵͳӦ�õ�Ҫ�����Ͻ���ѵ����ȷ�л���ʱ������ͨ������ֳ�����ӡ����̵�����Ч�������ǣ�������������������Ͻ���ѵ���Ļ���������ͬ����ʱ�����Ǻ�С�IJ��죬����ͨ������ָ�����ǡ�����ϵͳ����Ϸ����������ʾ��ǿ��Ĺ��ܣ�������ʵ����Ķ�̬������ʽ��������δ��֤�����㹻�ġ� �����뽫ǿ����������ҳ�֮Ϊ�㻭ʽ���ܽ��жԱȣ�����������������¶���Ч�������������������ȴʧ���ˣ������Ͽ����������ƣ���ij����Ԥ��ķ�ʽ��ͼ1չʾ��һ���Ӿ�ϵͳ�����Ӿ�ϵͳͨ������ʶ��У���������ڻ�ѩ�ĵ�·�У�����ʶ����У���������Ķ�ϵͳ���ң�������ȷ�ؽ���һЩ���ӣ������Ķ�������ȴʧ�ܡ������صĸ����  �κ����й�עAI�����˶�����ʶ������׳�Դ�һ��ʼ��һֱңң���ڡ������Ѿ�Ͷ���˾����Դ�������ѧϰ������δ��������⡣ �෴����ĿǰΪֹ�����ѧϰ������֤�������ݼ��ʣ�dz���������ҷ����������ޣ�Marcus��2018�������ߣ�����Francois Chollet��Chollet��2019�꣩�����˵���������˹�����һֱδ�ܴﵽ�����룺���������ܹ���Ƴ����ض������ϱ��ֳ�ɫ��ϵͳ����������Ȼ�������Եľ����ԣ������ԣ�����������������������ѵ���ݻ��ߵļ������в�ͬ�������������û�������о���Ա�Ĵ��������������������Լ��Ĺ�����ʽ��Ӧ����ӱ������ ��Facebook AI�о���Ա�ŶӵĻ�˵��Nieet al����2019�� ��Խ��Խ���֤�ݱ��������Ƚ���ģ��ѧ�����������ݼ��е����ͳ��ģʽ�������������������������ɸ�����ѧϰ���塣�� ����Yoshua Bengio�������һƪ���£�Bengio���ˣ�2019�꣩����ָ����������һ���ؼ��������ǵ���Ҫ������ѧϰ�����ƹ㵽ѵ���ֲ�֮��ʱ����ǰ�Ļ���ѧϰ�����ƺ��ܱ�����������ʵ����ͨ������Ҫ�ġ� �����������ܽ�AI������һ���µ�ˮƽ�� �� ����Ϊ����������ȿ��������Һ�ErnieDavis��˵����������ϵͳ�����������ǾͲ�����ǿ����鱨���ⲻ�����й����ͱ�������ݼ���ϸģʽ�����������һ����в鿴�κγ��������һЩ���⣬������߿��ܻ��ʣ�˭��ʲô��ʲô�ط���Ϊʲô����ʱ�Լ���Ρ� �����õ�һ�죬�㷺���۵�������GPT-2������ϵͳ���Բ������º����Ƶĸ�������Ƭ�Σ����Դ���������ƺ���ӳ���������Ķ��������磬����һ������Ƭ�Σ��Դ�����ʾ�������硰����ʿ���߽��ưɡ�����ͨ�����Բ�������������������ʵ�������У������ˣ��ưɣ����Ϻͽ�Ǯ֮��Ĺ�ϵ�� ����ʿ���߽�Ħ�ն���һ�Ҿưɣ������е�Ǯ�������˺Ⱦ��ϡ� ���ǣ���������GPT-2���ӿ�������ô����עĿ����ʵ�������ı�ʾ�ܵ����Ҳ��ɿ���������Nie���ˣ�2019����ָ����������ͨ�������м���»������Marcus��2020���������������Ͱ�����ȡ��������2019��12����NeurIPS��Marcus��2019��������Ŀ����л����ԡ� •�����Ұ��·����ڸ�ϴ�����ˣ���û���������ҵ��·��������������ķ���� •ԭľ������ֻ���ܡ���ֻ�뿪����ֻ���롣����ԭľ�ϵ���������ʮ�ߡ� ���ȣ�GPT-2������ȷԤ���ѯƬ�κ����Ԫ����𣨼�λ�ã����������ٸ�ϴλ�á��ڵڶ�ƪ�У�GPT-2�ٴ���ȷԤ������ȷ����Ӧ��������������Ϊ���֣��������ٴ�������ϸ�ڡ�����Marcus��Marcus��2020; Marcus��2019�������۵����������ִ���dz��ձ顣��Ȼ�����ǽ���Ҫ���ȶ��Ļ�����ʵ�ּ���ԡ� �� һ���վ���Ҫ�������Ȳ��������ѧϰ�������еĺ����ƽ�����Ϲ��ߣ��Լ��ռ������ѵ��������չ��Խ��Խ���GPU��TPU��Ⱥ����������ͨ���ռ���������ݼ����Ը��ַ�ʽ������Щ���ݼ��Լ��ڻ����ܹ���������ָĽ����Ľ���GPT-2������ϵͳ��������Щ�������м�ֵ������Ҫ���и�����������˼���� ���ܻ���ø��༤�ҵķ��������磬Yoshua BengioΪ�����չ���ѧϰ���߰���������ิ�ӵĽ��飬��������ͨ���Էֲ��仯��������ͳ����ȡ�����ϵ�ļ�����Bengio���ˣ�2019�����Զ���ȡģ�黯�ļ������ṹ��Goyal et al����2019�����Ҷ�ʮ��ͬ�顣 ������Ϊ�������������Ҫ��ǿ������ҩ��ر��ǣ����ĵĽ��飬�����DZ������¼��о����������ڿ���һ����ܣ����ڹ����ܹ������ȡ����ʾ�Ͳ�������֪ʶ��ϵͳ��ʹ����Щ֪ʶ�����������º��������ӵ��ⲿ�����ڲ�ģ�͡� �� ��ij��������˵���ҽ�Ҫ��ѯ���ǻع鵽�������⣺�����˹�����֪ʶ���ڲ�ģ�ͺ���������ϣ�����µķ�ʽ�����ִ��ļ�����������ǡ� ��Щ���ⶼ�Ǿ����˹����ܵĺ��ġ����磬Լ�������������Ŀ��������ġ������볣ʶ����Programs withCommon Sense����ָ���˳�ʶ֪ʶ�ļ�ֵ[McCarthy 1959]�����������أ�Doug Lenat������ʶ֪ʶ�Ļ���������ʽ��Ϊ�������Ĺ��������ͣ�Lenat��Prakash��&Shepherd��1985��Lenat��2019������TerryWinograd���ȸ贴ʼ��Larry Page��Sergey Brin�ĵ�ʦ����Ƶľ���AI��blocks world��ϵͳSHRLDUΧ��һ���ڲ��ġ��ɸ��µ�������֪ģ��չ������ģ�ͱ�ʾ������һ��ѵ����������λ�ú����Ե����⣨Winograd��1971����Ȼ��SHRLDU����Щ��֪ģ�ͽ����������Ա��ƶϳ�����ʱ������ƣ������״̬�� ���һ�»���ѧϰ�����������ĵı��⣬��ᷢ�ֺ�������������Щ�۵㡣һС�����˻��ᵽ��������һС�����˿��ܻ��ᵽʵ�ֳ�ʶ��Ը����������˻ᣨ����أ�ȱ���ḻ����֪ģ�ͣ�������˺����壬���ǵ����ԣ��Լ�����֮��Ĺ�ϵ�� ���磬һ����GPT-2������ϵͳ���������������飬�����Ǻ��ǻ���û���κ���ȷ�ģ�ֱ�ӱ�ʾ����ʱ�����ģ���ʶ֪ʶ��û���κ���ȷ��������Ҳû���κ�����ͼ���۵��������ȷ����֪ģ�͡� ��������Ϊ����ȱ���������������֪ʶ�����ơ�GPT-2�����Ƿ����ģ�����һ�ֵ�ǰ���Ƶ���������Զ�뾭���˹����ܵĹ�ע��ת��һ�ֲ�ͬ�ġ���Ϊ���������ķ�ʽ�����ַ�ʽ�������ѧϰ�ĸ������ƶ��ģ���Լ2012�꣩������DeepMind�����Ƴ��Atari��Ϸϵͳ��Mnihet al.��2015���ij��֣���һ���Ƽ��ٷ�չ��������������۵ģ���ϵͳ�ڲ�ʹ���κ���ϸ��֪ģ�͵�����³ɹ������˸��ָ�������Ϸ�� �����ǿ��ѧϰ�Ĵ�ʼ��֮һRich Sutton��һƪ��Ϊ�Ķ�����������ȷ����һ���ơ���ƪ��Ϊ��ʹ��Ľ�ѵ����������ȷ���鲻Ҫ���������֪ʶ�� ��70����˹������о��п��Եõ�������ѵ�ǣ����ü����һ�㷽������������Ч�ģ������ںܴ�̶��ϡ����о���Ա��ͼ��������Ը������֪ʶ�����ӳ�Զ������Ψһ��Ҫ�������ü��㡣������֪ʶ����������ʹ�������ӻ���ʹ���Dz�̫�ʺ��������ü����һ�㷽���� ��ij�̶ֳ��ϣ�������֪ʶ����������ѧϰϵͳ�������ڻ���ѧϰ�类��Ϊ���ף���ȻҲ����ȡ����DeepMind����Ӱ����������֮һ������Χ�����Ϸ������Ҫ����֪ʶ���У���Ŀ������ȫ��������֪ʶ���Ա㡰ѧϰ���Ʊ�����������ս����������̶ȡ���Silver���ˣ�2017��������ܴӴ��ģ�����Ͽ��й��ɳ���ʶ����������С������Լ������ô����ѧϰ������һ��Ⱥ�˽��dz����ˡ�����Ȼ��äĿ��ͬ������������˵��һ�У��������Լ��ķ�ʽ�������⡣����ConceptNet����Ҫά����Robyn Speer��˵�����ǵ�����׳־Ӧ�ø��ã�������ϣ�����������Ϊ���Զ�����˵�������õ��Զ�����˵����⡣����ϣ���ṩ�ģ�֪ʶ��������Ǽ�������õģ������ڵ�����Ҳ�ܺá���ģ����Ҳ��֤����һ����Ĺ����������ձ�Ŀ����ǣ������������һ�������������ɡ� �� �����ǣ���ʹ�д������ݣ�Ҳ����GPT-2��Radford���ˣ�2019��������Transformer��Vaswani���ˣ�2017�������Ļ����������������ռ���֪ʶ��Ȼ����ɢ�ĺ͵�״�ģ�����˵�����õģ���Ȼ����ӡ����̣�����Զ���ɿ���Marcus��2020���� ��������ӣ�������ϴ�õ��·����ڼ����Ȼ�����ܻ���������������ȷ��GPT-2�����ж����������ֲ��ɿ��Ͳ��ɿ������磺 ������Ʋ���ƿˮ��ˮ���ܻ������ ������Ʋ���ƿˮ��ˮ���ܻ�����һЩ�������ذ��ϡ�ˮ��������ݣ���ƿ���е�ˮ������ʱ���ݻ����͡� �����������һ��װ����߱��IJ���ƿ����߱����ܻ����������� ������Ҫ���ǣ����ٹ����á�ͨ�÷�������������֪ʶ�ļ�ֵ���������Է��������������Ϸ��������������ʶ�𣬶���ʶ���ǿ����Եġ���Go֮�����Ϸ�л�ʤ����ͺ��������Ź��»�����ʵ����������֮��ļƻ��������ͬ�����簢����13�Ż����ȷ��������Ա���ڵı�Σ�������Ͻ������������������ٺľ�������һ��һ���Խ���������ƺ���������֪ʶ�����ǿ��ѧϰ�����ܹ����ķ�Χ����Ҫ֪����ϴ�ص�������ʱ������ǰ�������һ�������죬�Ұ��·����ڸ�ϴ�����ˣ���û�м���������������Ҫһ��������ڲ�ģ�ͣ��Լ�һ������ʱ������Ƹ���ģ�͵ķ���������һЩ����ѧ�ҳ�Ϊ������µĹ��̣�Bender��Lascarides��2019������GPT-2������ϵͳ����û�������Ĺ��ܡ� ������ļ�������Ӧ���ڿ���ʽ������Ự��������Ͷ����������ʱ������Ͳ�����ȫ���ռƻ����С�������ǹ��ڼ�̺���ɢ�����ɿ��� ��ʱ��˼һ���ˣ�������ǽ��������ѧϰ�Ľ�ѵ���������֪ʶ����֪ģʽ�ٴγ�ΪѰ���˹����ܵ�һ���������ǵ�ϵͳ����ʲô���ӣ� 2��һ�ֻ�ϵġ�֪ʶ�����ġ�������֪ģ�͵ķ��� ������֪��ѧ�ң��������Լ�������һ��ѭ���ķ�ʽ���Դ���֪���л��壨�������ࣩ���ⲿ���ո�֪��Ϣ�����ǻ��ڶ���Ϣ�ĸ�֪�����ڲ���֪ģ�ͣ�Ȼ���������صľ��ߡ���Щ��֪ģ�ͣ����п��ܰ����й��ⲿ�����д����������͵�ʵ�壬���ǵ�������ʲô�Լ���Щʵ��֮����ι�������Ϣ����֪��ѧ���ձ���ʶ����������֪ģ�Ϳ��ܲ�������ȷ����Ҳ��������Ϊ�л�����ο�������Ĺؼ���Gallistel��1990�� Gallistel��King��2010������ʹ�Dz���������ʽ����֪ģ��Ҳ������Ϊ���������ָ�ϡ��ںܴ�̶��ϣ��л����������ϵķ��ٳ̶�ȡ������Щ�ڲ���֪ģ�͵����ó̶ȡ� ������Ϸʵ�����ǰ������Ƶ������еģ���ϵͳ����ij�������ڲ�ģ�ͣ����Ҹ�ģ�ͻ�����û����루�Լ���Ϸģ������������ʵ��Ļ�����ڽ��и��¡���Ϸ���ڲ�ģ�Ϳ��ܻ���ٽ�ɫ��λ�ã���ɫ�Ľ���״����������ȡ�����Ϸ�з��������飨�û����ض������ƶ����Ƿ�����ײ���Ǹ�ģ�Ͷ�̬���µĹ��ܡ� ����ѧ��ͨ������һ�����Ƶ�ѭ�����������ԣ������еĵ��ʱ�������һ�����ӳ�䵽һ�������ϣ��������ָ���˸���ʵ�������¼�֮������顣���������ڶ�̬��������ģ�ͣ����磬����ʵ��ĵ�ǰ״̬��λ�ã���������ѧ�����������Ȼ����ȫ�������������Ƶķ�ʽ���еģ���֪������ģ�͡��������ߡ�����Щ�������ر��Ƕ�����ץȡ�Ķ˵��˵����ѧϰ�������á��� ��ǰ������ǿ�ҡ�����ĵĹ۵��ǣ�������Dz������Ƶ����飬���ǾͲ���ɹ���Ѱ��ǿ������ܡ�������ǵ��˹�����ϵͳ�������ö����缰�䶯��ѧ�Ĵ���֪ʶ�����ⲿ����Ĺ�����ϸ���ṹ�����ڲ�ģ�ͽ������������������ǽ���Զ������GPT-2�����ǻ����ô�����������ݿ⣬��ȷ�ش���һЩ���飬�����Dz����������ڷ��������飬����Ҳ�����ܹ��������ǣ��ر��ǵ���ʵ�����е����ƫ��ѵ������ʱ���������Ǿ������������������GPT-2�����뷶Χ������������������������ı����룬�������ø�����Ҳ�������Ҳ���Ϊ�����������뷶Χ���ܽ��ϵͳȱ����ȷ���ڲ�ģ�͵ĸ������⡣ͬʱ��ֵ��ע����ǣ�äͯ��չ���ḻ���ڲ�ģ�ͣ�ѧϰ���൱��������Լ���ν�������Щģ����ϵ��������ȫû���Ӿ����루Landau��Gleitman��&Landau��2009������ �� Ϊ��ӵ���ܹ��Խ�׳�ķ�ʽ���������������ϵͳ��������Ҫʲô�����Ⱦ���������Ҫ�����ѧϰ����Ҫ������ѧϰ���;���AI������ע֪ʶ���������ڲ���֪ģ�ͣ�֮���������ϵ����������Ҫ��ʲô�� ��Ϊ�����˶������Կ��ǽ���������Ϊ�ϴ���ս�����Ʒ�����������ڹ���һ������ѧϰϵͳ����ϵͳ�������������������ù㷺��Χ�ĸ��������������������������ѵ���ԣ���������������ʾΪ���������� 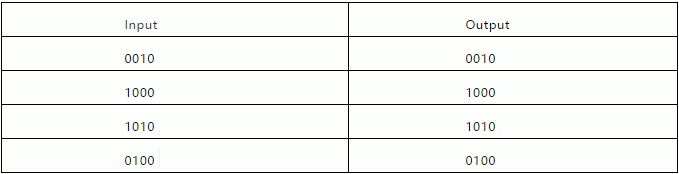 �����κ�����˵���ܿ�ͻᷢ��������һ����ͳ�ĸ�������Ϊ��������������ʽ����ѧ����f��x��= x +0���������°���[f��1111��= 1111; f��10101��= 10101����������]�� ���˾��ȵ��ǣ�һЩ��������ϵ�ṹ�����磬����֪���������һ���̿�������Ϊ���ѧϰ�ĵ������ӣ��������鷳������һ������֪����ʾ���������ڵײ�������ڶ������м���һ�����ز㡣�����κνӴ��������������˵����Ӧ�ÿ���������Ϥ��  �����������������ѧϰ����������������������ʵ���ϡ�ͨ�ú����ƽ����ĸ��ֶ��ɿ��Ա�֤��һ�㡣�����㹻��ѵ�����ݺ�ͨ��ѵ�����ݽ��е��㹻���������������������ѵ�����ݡ� ��һ��˳����ʱ�����磬����ܹ�������ȷ������û������ѧϰ�ľֲ���Сֵ�������������ƹ㵽����ʾ������Щʾ������Ҫ��������������ʾ�����ơ��ڡ���ѵ���䷶Χ�ڡ������磺 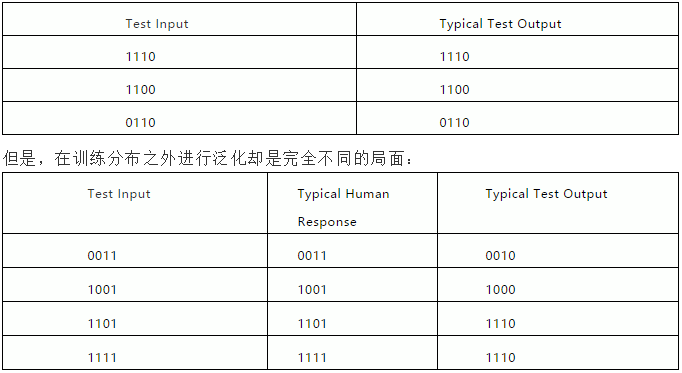 ���������ӱ�����������ѵ���ֲ���Χ�ڵİ����������ã�����֪��������Ͼ���û��ѧϰ�����ݹ�ϵ�����ͬһϵͳ�����ż����f��x��=x�Ͻ���ѵ�����Ὣ���ݺ�����չ���������ⲻ��ѵ���ֲ���Χ�ڣ�Marcus��1998�����ټ������ӣ�ÿ������ڵ㣬�������ұߵĴ����� 1��λ�Ľڵ㣬��Ӧ�����Ƶķ�ʽ���������Dz���������ߵ�λ����Ϊ���ұߵ�λ�ij�������������ѵ���Ķ���֪���Բ�ͬ�Ķ����з�Ӧ�����ұߵĽڵ�ʼ��Ϊ�㣬������罫����Ԥ�����ұߵĽڵ㽫ʼ��Ϊ�㣬�����������������Σ����磬�ó�f��1111��=1110�����������Լ����صķ�ʽ�����˸���������δ����������Ȼ�ᷢ�������ݹ�ϵ�� �������ز㲻��ı��������Ϊ��Marcus��1998�������Ӿ��и���ڵ�����ز�Ҳ����ı䣨Marcus��1998������Ȼ�����Խ����������Ľ�����������һ��������ض������⣨����ż����������ʾ����ѧϰ���ݣ������������ʹ�ü�����ʾ����������˵��Ŀ�ģ�������ѵ���ֲ�֮��������Ƶ�������ձ飬����Խ��Խ�õ��Ͽɡ�JoelGrus�����������һ�����Ƶ����ӣ���Ϸfizz buzz��Lake and Baroni��Lake&Baroni��2017��չʾ��һЩ�ִ���Ȼ����ϵͳ��������ܵ����������Ӱ�죬���Ը��ַ�ʽ������ģʽ����Ϊ�µ��ʡ�Bengio�������NeurIPS�ݽ���Bengio��2019���ж��ִ��������������������������ơ��ڹ淶��������ܹ��У��㷺�Ĺ��ԣ���ͬһ�ԣ��ķǾ�����չ�Ƿdz��ձ�ģ����ҿ���������Ȼ�ǽ�չ����Ҫ�ϰ��� �� �ӱ����Ͻ���ijЩ������ִ������磨����˴����۹��ķ���ѵ���Ķ���֪��������������ֳ�ɫ������ѵ��ʾ�����Լ���Χ����Щʾ���ĵ����ڲ�㣬��Щ��Χ�Ƴ�ά�ռ��ijЩ�أ��ҳ�֮Ϊ����ѵ�ռ��н��и�������������ѵ�ռ�֮�⣨��Bengio�Ĵ���У�����ѵ�ֲ����У����ǵ��ƹ�Ч���ܲ 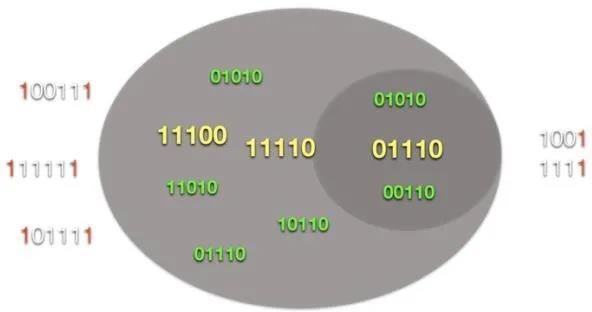 ����֪����������ѵ�������ռ����ƹ㣬����������ѵ�������ռ����ƹ�ͬһ�Ժ����� ����dz���������������ص����⣺ 1.���ʣ��ڿ���ʽ�����У����ϵͳȱ���ɿ��ķ�������������ѵ��ʾ���ռ�����ݣ�����������Щϵͳ��������ÿ��������ϵͳ����һ�������ƽ�������ôĿǰ���е�ϵͳ�����ó��ڼ���ʾ���������ó���ѵ��ʾ�����������ࣨ���ܲ���ȫ����ʾ������ʹ�����Ƕ���Χ�Ʒ��������Ӧ�ó�������á����ǣ����������ѵ��Χ�����Ǿͺ����ˡ����磬�����һ����ѧѧϰϵͳ�ó���1+1=2��1+1+1=3��1+1+1+1+1=6������1+1+1+1+1+1+1=7�����и���������ж�ʧ���ˡ�������һ�£���һ������������б�дһ��FORѭ��������ֻ��С��7�ļ�����ֵ��������ִ�У��������֮�£���Excel��Flash-fill��һ�ֻ��ڹ��ɳ����ۺϵķ���ϵͳ������������¸���Ч��Polozov&Gulwani��2015���� 2.��������ѵ���ƶȵľ���ϸ����������������������ѧϰ�߶����������ǵ�ĸ��Ͷ���������⣬�����ܻ���ǧ�����������������ȷ�е�ϸ�ڷdz����У�����ѵ����Ŀ�ij���˳�������һƪ���������硰�γ̡������ף���ͬ���أ���ʮ���������Ѿ�֪�������������ܵ������Ը��ŵ�Ӱ�죬�����ڵĹ����������Ĺ������ǣ�McCloskey&Cohen��1989������ʹ�����Ƕ���Ŀ���ֵ�˳��dz����С�DZ�ڵĽ���������ڶ��������McClelland��2019�꣩����������Ȼ���ڡ�ͬ�������������һƪ���ģ�Hillet al.��2019����˵����������ֳ��ķ����̶��ںܴ�̶���ȡ���ڸ�������ʵ�����Ļ���ϸ�ڡ��� �� ���ʺ����ƶϳ���ѵ���ֲ���Χ���������ೣʶ��֪ʶ���ձ�����ì�ܡ���Ҳʹ�����ϵ���Թ���������Pearl��Mackenzie��Pearl��Mackenzie��2018���� ����������չһ�����ӣ��������ͨ�ij����˺Ͷ�ͯ����ʶ��������Ǵ��ض��ľ����еó��ģ����³���������������ȷ�ģ������������һ��ʢװҺ���ƿ�ӣ�һЩҺ�彫�ᣨ�����������ڷ�������ȣ����ܻ�Խ��ƿ�ӡ� �����������dz���ģ���Ϊ���Dz���������ijЩ�ض���Ŀ�����������ڴ��͵ģ�����Ա�����ʵ����𣬶���ƿ�ӵ���ɫ����״��ƿ�ӵĴ�С�أ�����ƿ���Ƿ�װ��ˮ�����ȣ���Ѱ���������ϡ�����ϣ������װ�й�����л���Ϸ���ӵ�ƿ��Ҳ�������Ƶĸ�������ʹ������ǰ������ƿ�ӵľ��鼸��ֻ�漰ʢװҺ���ƿ�ӡ� ����ÿ����Ҳ������ʶ�����¸����Dz���ʵ�ʵģ������������һ��ʢװҺ���ƿ�ӣ���ôһЩҺ�壨������������ȣ����ܻ����300�ס� ͬ�������۸��˾�����Σ����Ƕ�����ͨ�����ַ�ʽ��չ��֪ʶ����Ϊ���ڴ�С��һ��ƿ�ӣ���������ǰ������ƿ�Ӵ��С��ƿ�ӣ��������Ŷ���̫���ܳ����� �����������ϣ�������δ����Ͳ��ݲ���ó����֪ʶ�������漰�ض�ʵ�壬���漰���������ࣿ ���Ƶ���ս��ζ������ѵ���Ķ���֪��������ͨ�ù��߱����������ʺϸù����Ĺ��ߡ��෴�����DZ����ҵ�һ������Ļ�����ѧϰ����ʾ����չ����֪ʶ�� 2.1��ϼܹ�2.1.1�����ϵķ��������ṩ��Ψһ����֪�������������������Ǿ��� ������������ϵķ��������ṩ��һ��DZ�ڵĴ�-ÿ�켸��ÿ��ʹ�������ڴεĽ�����������������������������Ļ������ر��ǣ�ʵ���ϣ�ÿ������������ĸ��������������ʵ������������ʵ���İ��Լ��Ա����IJ����� ��Щ�뷨�е�ÿһ������Сѧ��������Ϥ�ģ�������x��y������ʵ���DZ������ض����֣�2��3.5�ȣ�����Щ�������ܰ�ʵ�������磬x��ǰ���ܵ���3�������������ӷ��ͳ˷�����Щʹ�ÿ��Ա�ʾ����y = x + 2֮��Ĺ�ϵ����Щ��ϵ�Զ���չ��ij�����е�����ֵ�����磬�������֣������������ӵ�ʵ���Ĺ�����ʱҲ��Ϊ������ ��Ȼ������������ǽ�����ͬһ����ʯ�ϵġ��㷨��Ҫ�Ǹ��ݶԱ���ִ�еIJ�����ָ���ġ���������ʵ���������㷨��ִ�в�����������ֵ�� ��Ҫ���ǣ����IJ�����ָ����ʽͨ��������ij���������ʵ�����������������������ַ��������и������������IJ���ͨ������һЩ�������������������㣨�ӷ����˷��ȣ����Ƚϣ�x��ֵ�Ƿ����y��ֵ���Ϳ��ƽṹ���Ա���n��ǰ�����κ�ִֵ��n�β��������x��ֵ����y��ֵ����ѡ��ѡ����a��������ѡ��ѡ����b�ȣ���һ�����ƣ�����bug������Ա���еĴ���ȣ�������ζ����ȷʵ�ֵĺ���������ij�����е��������룬��ȫ���������ǿ��ܱ�¶�ڻ�¶�ڵ����롣 ֵ��ע����ǣ����ָ��ݲ�������Ĺ��ܶ�������ķ������������ѧϰ��ȫ��ͬ�ķ���������ѧϰϵͳͨ��ͨ��Judea Pearl�������������ϵĹ�����ѧϰ��������������������صĺ�����������Աͨ�����ݱ�����������������ѵ���������������㷨������˵�����Ѿ��ܺõط����ڴ�ͳ�ļ��������Ա��֧�ִӲ���ϵͳ��Web���������Ƶ��Ϸ�ٵ����ӱ���ȵ��������ݡ� ������Ҫ���ǣ�ͨ����ϵͳ�Ա����ĺ��IJ�������Ϊ�����ھ����ϵͳ�ع��������磬�������е�ѭ����λ�����Ļ�������һ�鲢�е��Ӳ�������ģ�ÿ���Ӳ���һ��λ��ֱ���������ֵĿ��ȡ�������ǰ�Ƿ�ʹ�ù��ò��������������ͬ���������ѧϰ������Ա���Է��ĵ�Ԥ�ڣ����۾�����Σ������������������ã��������۾�����Σ����������Դ˷�ʽ�������С�������Щ���ƣ�������ʵ�����Ͳ��������ŵ����ڣ�����������Ա��ij�ֳ���ָ���������ij�ֿɿ�����Ϊ����Ʒ�� �ܵ���˵�����ڱ�������ʵ���ͶԱ����IJ��������ĸ����蹹���˷��Ų��ݵĺ��ģ�Newell��1980�� Marcus��2001���������ű���ֻ�Ƕ�����ϵͳʹ�õ�������б���ļ�ʽ���������ڱ�ʾASCII�����е���ĸ�Ķ���������ģʽ���������������е�����ڵ��ʾ�ض����ʵı��������֪��Ŀǰ���е�ϵͳ��ʹ�����ǣ������Marcus 2001����2�¡�ijЩ���Ŵ���ϵͳ����ֻ�������IJ���������ӷ������ӺͱȽϣ�����һЩ���ſ��ܾ��и��ḻ�IJ��������磬��������ʽ��ͳһ���������������Ĵ�С����������ͬһ�������ǵĺ���ָ��������ڷ��Ŵ�����ϵ�ṹ�Ϲ����ݹ飬���Ⲣ���Ǿ��Ե���Ҫ�� ��������˵��Marcus��2001��Marcus��1998��Marcus��Vijayan��Bandi Rao����Vishton��1999��Berent��Marcus��Shimron����Gafos��2002��Berent��Vaknin����Marcus��2007����ij����ʽ�ķ��Ų����ƺ���������֪�DZز����ٵģ����統һ������ѧ����һ�ֳ��������ģʽ������һ������������Ĵʵĺ�����Ա�����Ӧ��������ļ�ͥ�����ߵ�һ����������һ����ӱ�ķ�ʽ��չ��һ����Ϥ������ģʽ�����ַ�ʽ��Խ��ѵ���ֲ���Berent et al.��2002��Berent et al.��2007����һЩ��������֤������1999���һ���о���Marcus���ˡ���1999�꣩���ҵ�ͬ�º���չʾ��7���´��Ӥ���ܹ�ʶ��ij���ģʽ�������������е�ABBģʽ���������Ǵ�һ��ѵ���������ƶϳ���ȫ�ɲ�ͬ������ɵ����ַ�������Щ�����������������ǵ�ѵ����û���ص��������о���������ʹ���������ƺ�Ҳ���������������ƶϡ�Gallistel��King��Gallistel��King��2010����Ϊ�����Ĵ洢�ͼ������ڶ�����֪������Ҫ�����磬�۷��ƺ��ܹ���̫����λ�ǹ�����չ������δ���Ӵ����Ĺ�����������Dyer��Dickinson��1994�꣩�� ���Ŵ�����ͨ�û���ҲΪ�ṹ����ʾ�ṩ�˻�����Marcus��2001�������磬���������ͨ��ʹ���ɷ��Ź��ɵ����νṹ����Щ����ͨ���Ա����IJ�����϶��ɣ��Ա�ʾ���ָ�������������νṹ�ļ��л�Ŀ¼���� ͬ�������Ų��ݵĻ����������ٸ�����ʱ��仯�����ԣ����磬�����ݿ��¼����ʽ������Щ�����ƺ������������ԣ���ݹ���ӽṹ���Լ�����ʱ��ı仯���Ը���Ͷ�����˽�������Ҫ��Marcus��2001������������˼ά���ĵ�5���ṩ��һЩʾ������Щʾ����������������ģ�͵ķ�Χ֮�⣬��������ʾ��������ʵ������ʱ������ƶ����ڡ������ֻ��Ʒdz�ǿ�����������е�Web����������������еIJ���ϵͳ�����������е�Ӧ�ó���ȶ�����������֮�ϡ� �����з�����ζ���ǣ�����������������������Ĺ淶��ִ���ж�ʹ������ͬ�Ĺ��ߣ����� �� Ȼ��������ʷ�ϣ����������ѧϰ�ںܴ�̶�����ͼ���ѷ��Ų��ݻ��ƣ������ֻ�������������رܵģ�����Ϊʲô�������ṩ��һ��������䷶ʽ�ĺ��ٵ�һ���֡�³÷�����غ����������1986��#39979������������PDP�鼮�У������Ų�����Ϊһ�ֱ�Ե���������������ı��ʡ�2015�꣬���ٽ����ű������������̫������Ϊ����������Ϊ�˹����ܵ�һ����ɲ��ֵ����ǣ� ��Ϊ�Ⲩֻ��ͨ���ڷ������̫����ɸ��Ŷ���̫���д�����������Dz���ȷ�ġ������ѧ�ҡ����������ŷ��ĵ�����ȷ��������ˣ�����ֻ֪������֪�������������Ե�ϵͳ�� ���˾��ȵ��ǣ����������ϵĴ���������Ҳȱ�ٸ��˵����ݿ�ʽ��¼֮����뷨�������ں�С���о��з����������νṹ������֮��ĸ��ӽṹ����ʾ��ʽ���������ߵĹ淶���������Ǽ�ʸ�����άλͼ��������ر�������Ը��˵ķֲ����ݽṹ�ͼ�¼����DeepMind��Ȥ����MEMO�ܹ���Banino���ˣ�2020�꣩����������һ����¼���ݿ⡣�� ����һ��Ҫ���������磬ԭ���ϣ����ǿ��Գ��Թ�������Ų��ݼ��ݵ���������õ������еġ�ʵ���������塱��Ҳ���Գ��Խ�����֮���ݵ������硣�����������Ų���ԭ������������ϵ�� ��Ȩ����
1����ƽ̨������Ʒ����ͼƬ��ƵΪ�û��ϴ�����������ƽ̨���ṩ��Ϣ�洢�ռ����
2����ƽ̨������Ʒ�ɸ���Ʒ���߷���������Ʒ�����뱾ƽ̨������Ʒ��ذ�Ȩ�� 3��������λ�����ʹ�á�ת�ػ�����ʱ����ͬʱ���ø���Ʒ���ߺͱ�ƽ̨��ͬ�⣻ 4����Ʒ������е�һ������Ʒ������ֱ�ӻ��ӵ��µķ������Σ� 5����Ʒ��������ת��������ý�壬������������ƽ̨��ͬ��۵�Ͷ�����ʵ�Ը��� 6������Ʒ�ַ����κΰ�Ȩ���⣬��������֪��ƽ̨����ƽ̨����ʱɾ�������������Ǹ�⣻ 7����ƽ̨����Ա�Ͱ�����Ȩ������֪ͨ����ɾ��Υ��ƽ̨����Ʒ�� |
 |��ϵ����|��������|�û�Э��|AMT��ѯ|�������|��Ա��פ|���ֳ�ֵ|�����̳�|���ֽ�������|TradExȫ��|����QQ����Ⱥ|������ҵ��|�����ż���Ⱥ|����Ͷ��|�ֻ���|
�����Ƚ����켼����̳™�����AMT™�� ����֪��™��
( ��ICP��12020441��-3 )
|��ϵ����|��������|�û�Э��|AMT��ѯ|�������|��Ա��פ|���ֳ�ֵ|�����̳�|���ֽ�������|TradExȫ��|����QQ����Ⱥ|������ҵ��|�����ż���Ⱥ|����Ͷ��|�ֻ���|
�����Ƚ����켼����̳™�����AMT™�� ����֪��™��
( ��ICP��12020441��-3 )
GMT+8, 2025-1-26 14:39 , Processed in 0.027039 second(s), 17 queries , Redis On.
��̳������ �����Ƚ����켼����̳������֪���� ���������Է�Ӯ������̳�������Ƿ����ۡ��Ƿ�������Ϣ����л������
����̳���۴��������߸�������һ�Ա�����е��������ݵķ������Σ��뱾��̳�����أ���Ա���뱾��̳���۱��������л��������ɷ��棬���漰�������ۡ�ɫ�顢��Ʒ��Υ��ǹ֧���۵���Ϣһ��ɾ��������������Ϻ�Э���й�ִ�����صĵ��飬�����л�Աע�⣡
����̳��Դ�ɻ�Ա�ڱ���̳��������Ȩ����ԭ���ߣ���̳������ԴΪ��Ա����ѧϰʹ�ã������漰��ҵ��;���������غ�24Сʱɾ���������ַ�ԭ���ߵİ�Ȩ��֪ʶ��Ȩ�������Ÿ�֪�����ǽ��������������ͻظ���лл������
������ϵ: ˫��QQ�ͷ���3419347041 ����QQ�ͷ�:3500763653 �绰021-37709287 ��������Ͷ�ߣ�QQ:2969954637 ����:info@amtbbs.org �Ź��ں�:AMTBBS







{kind=link}